


Data transformation is often one of the most complex parts of building stable, scalable workflows. Roboshift addresses these challenges through an AI-based platform that reduces manual effort in tasks such as ingestion, validation, reconciliation, and final output creation. By linking powerful logic with a structured pipeline, Roboshift guides teams away from writing massive custom scripts and toward a more efficient approach to data transformations and data management.
Why use ETL tools
Organizations typically draw on many information sources—CRM platforms, spreadsheets, financial databases, and sometimes proprietary solutions. Each source can have wildly different formatting and naming conventions. A robust ETL (extract, transform, load) framework helps ensure that the data from each source is harmonized before it ends up in your final system.
So here are 3 key reasons to use an ETL tool:
Efficiency: ETL helps remove manual labor from repetitive mapping tasks, freeing professionals to focus on high-level strategy.
Data consistency: Automated checks detect errors and inconsistencies early, reducing the risk of poor-quality data downstream.
Scalability: As data volumes grow, so does the complexity of merging, cleaning, and loading. A dedicated ETL service like Roboshift supports this expansion.
Roboshift specifically targets these needs by applying AI logic to standardize fields, eliminate redundancies, and give teams confidence that data is processed correctly. It supports offline multi-model (e.g., Llama, Pi, DeepSeek) and cost-efficient AI models for different stages. and ensures accuracy and consistency at every step. The AI usage is optimized for specific transformation requirements and no production data is exposed to the LLM. (offline LLMs and native cloud supported).
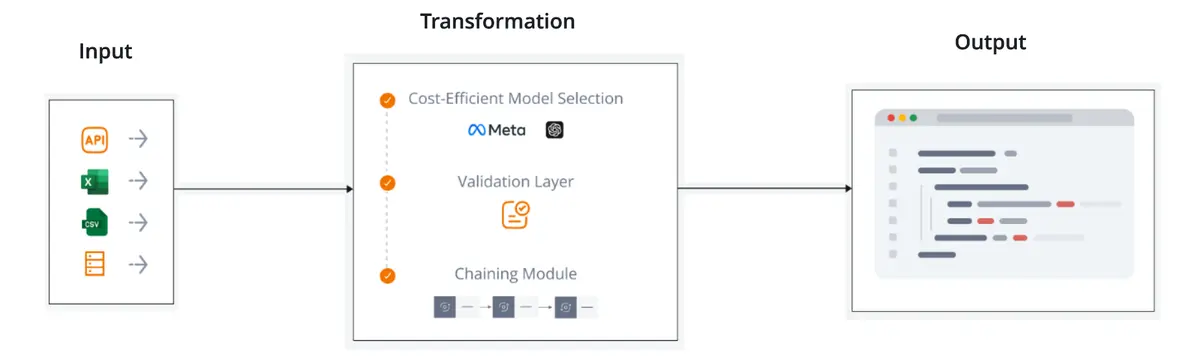
Primary components of Roboshift’s data transformation service
Roboshift’s architecture brings multiple layers of functionality together, forming a cohesive ETL process:
Data ingestion from numerous sources
Organizations often rely on CSV files or spreadsheets for day-to-day operations. Roboshift automatically recognizes these formats and organizes each record, preparing it for subsequent steps such as validation or reconciliation.
Ai-driven mapping logic
Traditional ETL methods demand extensive manual instructions. Roboshift significantly reduces that need:Adaptive matching: Roboshift scans data dictionaries and merges them with user guidelines to suggest column mappings.
Fewer explicit rules: Instead of “column a must go to column b,” you provide broad statements like “map all id fields to staff references.”
Reduced maintenance: Updating data sources is easier because Roboshift automatically adjusts mappings if new columns appear or old ones are renamed.
Built-in validations
Roboshift applies user-defined or system-defined checks to each row:Format checks: Verifies that dates or numeric fields follow specified patterns.
Value lists: It restricts certain columns to recognized sets, like “married,” “single,” “divorced,” etc.
Cross-file dependence: Compares references in one file to records in another and flags mismatches.
Reconciliation across multiple files
Roboshift’s reconciliation layer cross-verifies references by applying near-natural language rules, preventing discrepancies when data is spread among multiple sources.Automated output generation
Roboshift builds outputs that match your system requirements. Valid records often go to a “load” file, while problematic rows are sent to a “non-load” or “error” file.
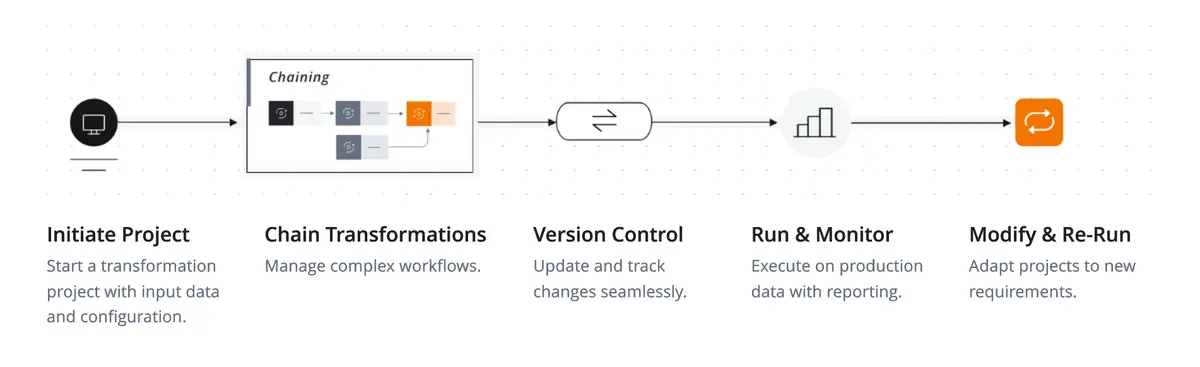
How Roboshift’s workflow operates
Though each organization’s setup can differ, Roboshift follows a clear path:
Data input: Raw files feed into Roboshift’s ingestion module.
Automated mapping: The platform references data dictionaries or user rules to align columns.
Validation: Each row is checked for format, range, or reference issues.
Reconciliation: Multi-file logic ensures that records match across sources.
Output: Clean rows populate a final “load” file; errors and warnings appear in a separate “non-load” file.
AI-based mapping in depth
A common roadblock for ETL teams is writing intricate scripts for each data relationship. Roboshift solves this by letting you define overarching guidelines that the AI interprets.
Interpreting data dictionaries: Roboshift scans column names, data types, and usage examples, connecting them logically.
Observing patterns: Consistent mappings—like “empid” in one file to “employee_no” in another—teach Roboshift how to handle similar cases in future runs.
User override: If Roboshift proposes an incorrect mapping, you can fix it. Over time, these corrections refine the AI engine’s suggestions.
Validations for reliable data
Roboshift checks each field, classifying issues as warnings or errors. Missing required fields, incorrect date formats, or invalid cross-references all emerge at this stage. Roboshift prevents inaccurate data from reaching your core systems by removing defective rows from the main pipeline.
Reconciliation for large data projects
Beyond per-field validation, Roboshift ensures that entire records across multiple files make sense collectively. If a user ID appears in one file, Roboshift checks whether related records exist in another. This layer is crucial for preserving logical consistency in scenarios like financial reconciliations or hr workflows involving multiple source systems.
Roboshift subscription model and licensing
Roboshift usually combines a base license fee with usage-based or value-based pricing:
License fee: Often linked to how much manual effort is saved.
Support tiers: First- or second-line support for different levels of technical assistance.
Optional development: Specialized logic or integrations can be added by the Roboshift team or a partner.
Some industries require strict control over data though. In that case, Roboshift offers an offline mode so you can keep your data within a private environment:
Local AI models: No need to send information outside your own servers.
Reduced compliance risk: Eliminates concerns about external cloud dependencies.
Configurable architecture: On-premises or private cloud setups are supported.
Incorporating Roboshift into existing pipelines
Introducing a new ETL system should not disrupt established practices. A typical rollout involves:
Pilot: Setting up of Roboshift for a small subset of data.
Configuration: Fine-tuning of mapping, validations, or reconciliation rules.
Training: Teaching staff how to manage rules, monitor logs, and handle errors.
Scaling up: Expanding Roboshift across more data sources after successful testing.
Multi-step workflows for complex transformations
Some use cases involve chaining multiple processing phases. Roboshift accommodates these by creating separate transformation steps and passing results from one to the next. Version control helps revert if a newly introduced rule disrupts the final output.
Balancing automation with human expertise
Even with AI-driven mapping, domain experts remain vital. You can override questionable mappings, add custom checks, and interpret error logs. This approach ensures your organization’s business logic remains accurate.
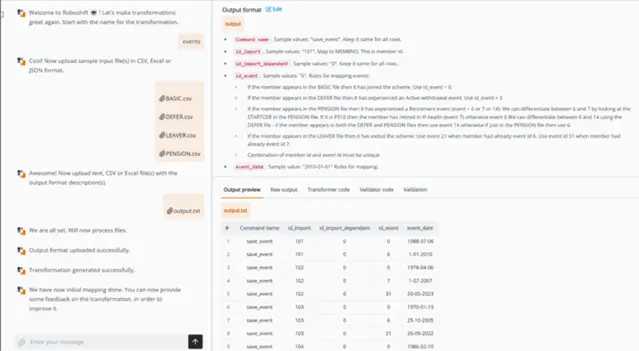
Ensuring data integrity with validation and error outputs
Roboshift’s error outputs let you import only the valid data while setting aside problematic rows for later review. This prevents a small number of flawed entries from blocking the rest.
Roboshift supports a range of outputs:
Load file: Valid records suitable for immediate import.
Error file: Detailed reason codes for problem rows.
Summary report: Quick view of processed rows, warnings, and errors.
Continuous improvement and analytics
Each transformation run produces logs that detail row counts, warnings, and errors. By studying these logs, teams refine rules and correct recurring issues, achieving cleaner data with each iteration.
Practical applications and examples
HR consolidation: Combining employee data from payroll, benefits, and scheduling systems.
Sales analysis: Normalizing data from multiple e-commerce platforms for consistent reporting.
Regulatory compliance: Updating and transforming data to adhere to regulatory and legal requirements.
Legacy migrations: Modernizing old database structures without manually rewriting each mapping rule.
Speed up your data transformations with Roboshift
Roboshift unifies AI logic, validations, and reconciliation into a single ETL solution that significantly cuts down on manual coding thanks to its intuitive generative-AI-based user interface. It processes diverse datasets securely—also in offline mode—and produces error-free outputs that are ready to load. By combining automation with the oversight of domain experts, Roboshift delivers dependable data pipelines that can scale alongside an organization’s changing requirements.
Blocshop continues to enhance Roboshift, expanding file-format support, refining AI-based inference, and adding features for deeper reconciliation. New user requirements often shape the roadmap, ensuring updates address real-world challenges, esp. in regulatory industries.
Want to learn more about Roboshift? Contact us for a free consultation.



